December 20, 2024•15 min read
Understanding the Model Context Protocol (MCP): The USB-C for AI Applications
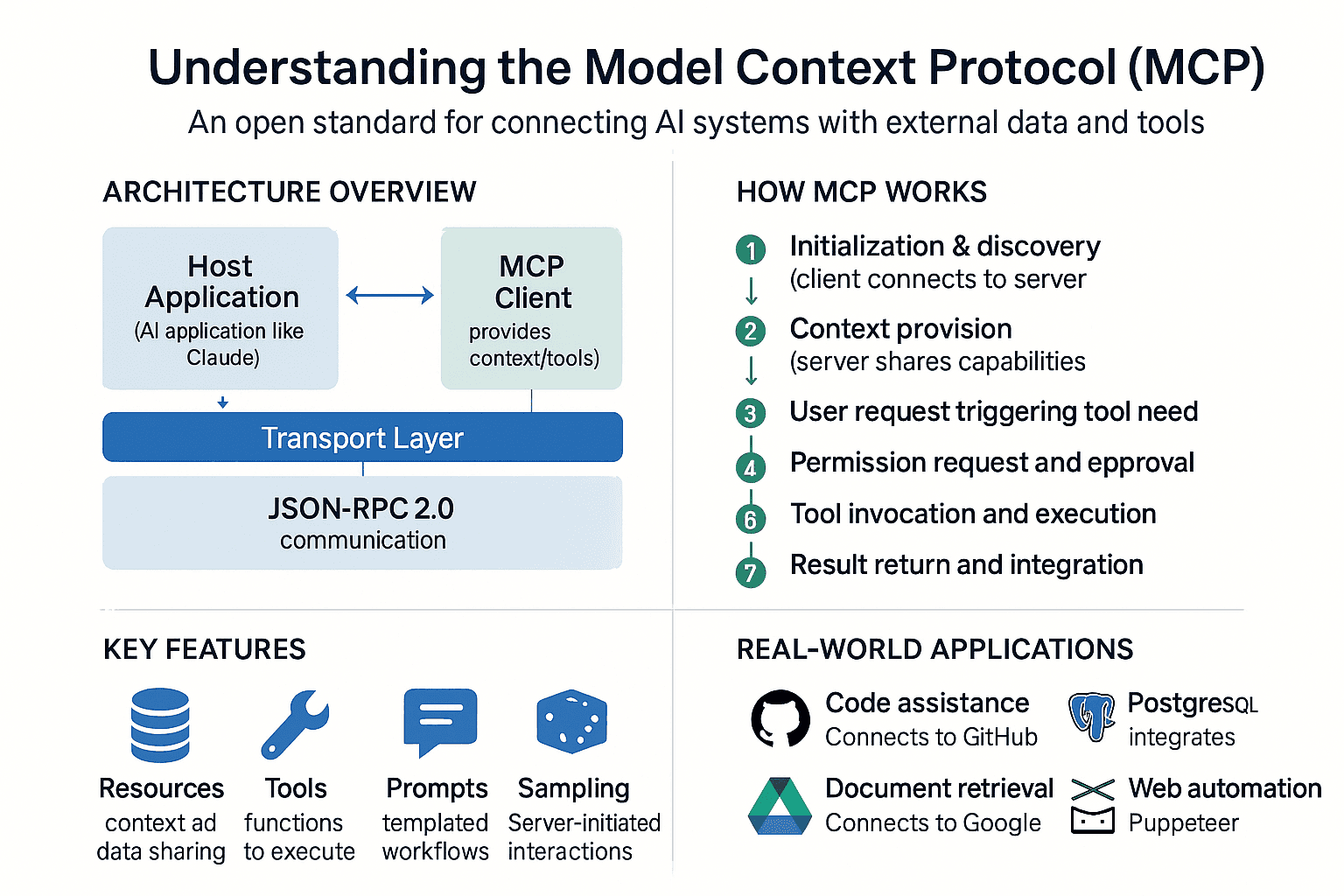
Explaining MCP with real world analogy
Read moreA Software Engineer who specializes in Data and AI/ML product development.

Hello there!! Ever wondered who's behind those smart AI systems you hear about? A Data Architect crafting elegant information flows? A Machine Learning Maverick pushing the boundaries of what's possible? Or maybe an AI Product Pioneer bringing intelligence to life? While I wouldn't claim all those grand titles (yet!), I'm deeply immersed in the journey of making them a reality.
On a more serious note, I'm a recent Master's graduate in Applied Computer Science from Concordia University, with a keen focus on engineering intelligent, data-driven products. My passion lies in the end-to-end creation of AI solutions, from architecting the foundational scalable data pipelines that ensure data integrity and flow, to building and deploying advanced deep learning models that deliver tangible value in production environments.
My hands-on experience has centered on constructing data infrastructures that can handle real-world demands and on operationalizing complex AI models that make a difference. I find immense satisfaction in translating theoretical AI concepts into practical applications that solve problems and drive innovation.
When the algorithms are resting (and my comments are finally all written), you might find me diligently practicing my French (oui, c'est un défi!), deep in the competitive arenas of Apex Legends trying to clutch that win, or even out on the volleyball court.
October 2024 - January 2025

An end-to-end data pipeline that tries to replicate Spotify Wrapped functionality with a PowerBI dashboard, allowing users to view their personalized music insights at any time. The pipeline extracts data from the Spotify Web API, processes it using modern data engineering technologies, and presents user-friendly visualizations.

This project presents the creation of a seamless data pipeline on Azure, orchestrated with PySpark, Azure Data Lake Storage (ADLS), Azure Databricks, and Azure Data Factory. The pipeline guides data through its transformation from the raw bronze stage to the refined gold layer, utilizing incremental loading and establishing external tables for in-depth analytics. At its core, Delta Lake, an open-source storage layer, guarantees ACID transactions.

This study compares discrete versus continuous audio representations for keyword spotting, finding that while WavLM's continuous features achieved superior accuracy (0.92% error rate), discrete EnCodec representations demonstrated potential with sequence-based models despite information capture limitations.

This project achieved second place in a competition classifying CIFAR-10 images with only 50 training samples by comparing machine learning models (70% accuracy), custom neural networks (79.28%), and transfer learning (92% with ImageNet pre-training), demonstrating effective strategies for learning from extremely limited data.

LanguageMate is an innovative AI-powered voice assistant designed to seamlessly handle multilingual voice interactions. The system integrates automatic speech recognition (ASR), natural language processing (NLP) via a large language model (LLM), and text-to-speech (TTS) technologies to provide a comprehensive conversational experience.

A Retrieval-Augmented Generation (RAG) application focused on financial data analysis 📈, built with Python, LangChain, Ollama, and Streamlit. This application leverages the power of Large Language Models (LLMs) combined with a specialized vector database (ChromaDB) 🧠 to generate summaries and calculate important metrics based on the annual and quaterly returns filed by the company. It uses LangChain to orchestrate the complex RAG pipeline, Ollama for seamless integration with local LLMs , and Streamlit to provide a sleek, user-friendly web interface

This project benchmarks three CNN architectures-ResNet-18, GoogLeNet and AlexNet-on three small image datasets (Vegetable Images, Freiburg Groceries and Grocery Store) using data-augmentation (flips, rotations, normalization), transfer learning, batch normalization, dropout and Adam optimization to maximize classification accuracy.
Explaining MCP with real world analogy
Read moreHave a question or want to work together? Feel free to reach out to me using the form below.